深度学习教程(附源码)
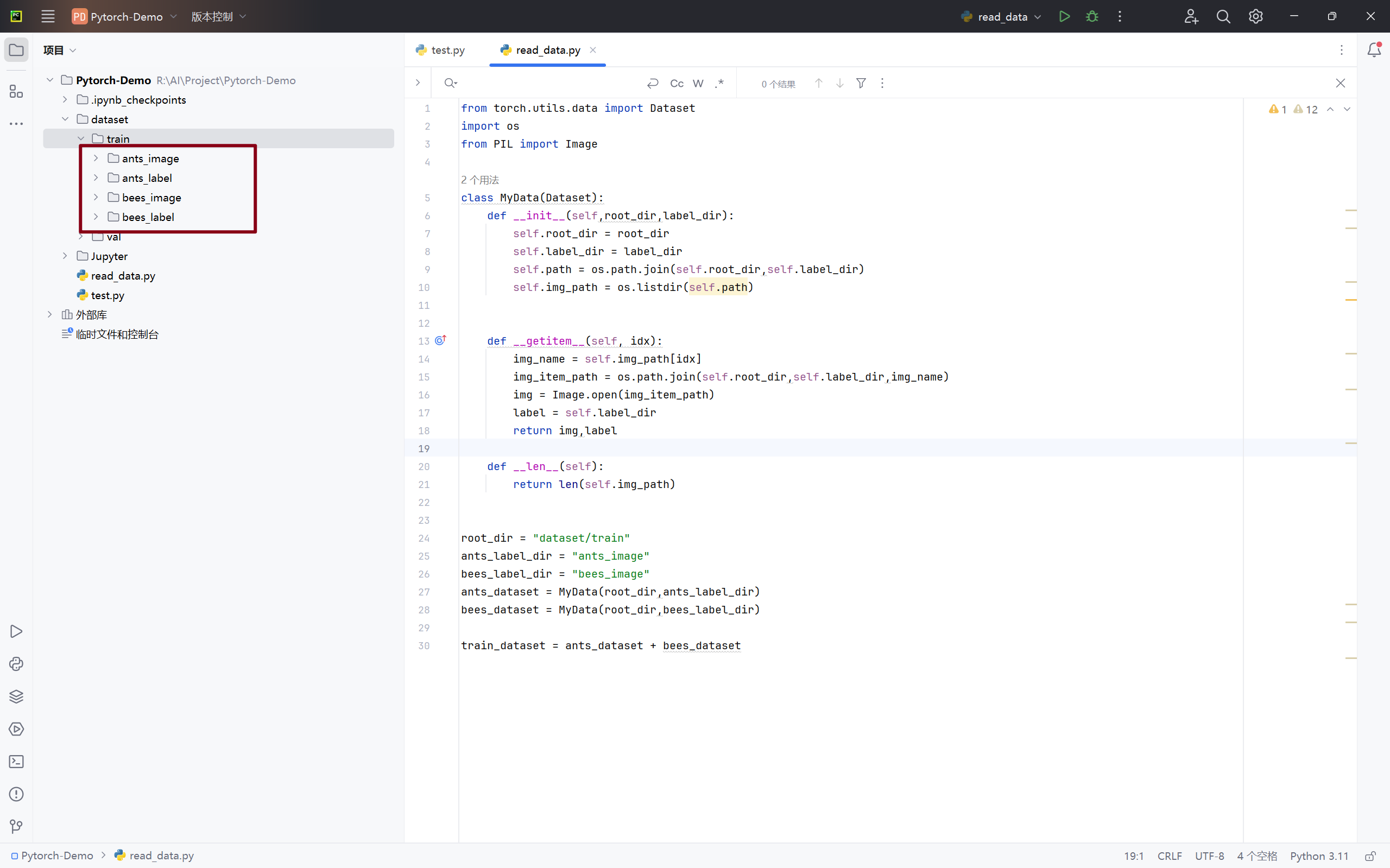
1.自定义数据集的设置/应用
1 | |
2.TensorBoard的使用
- 探究模型在不同阶段是如何输出的
简介
开发和训练深度学习模型时,你常常会遇到以下挑战:
- 训练过程不透明: 模型在**“黑箱”**中训练,你不知道内部发生了什么(损失下降了吗?过拟合了吗?梯度爆炸了吗?)。
- 调试困难: 当模型表现不如预期时,很难定位问题根源(是数据问题、模型架构问题、超参数问题还是代码bug?)。
- 超参数调整耗时: 手动尝试不同的学习率、批次大小、网络层数等参数并比较结果非常低效。
- 理解模型行为: 模型学到了什么?它关注输入数据的哪些部分?决策依据是什么?
- 比较模型: 当你有多个模型变体或实验时,直观地比较它们的性能很困难。
TensorBoard 就是为了解决这些问题而生的。 它通过将模型训练过程中的各种指标、数据和结构可视化,为开发者提供了一个直观的“仪表盘”,让训练过程变得透明、可解释、可调试和可优化。
使用
安装:pip install tensorboard
运行(不指定 port 的话默认 6006 端口)
1 | |
实例
1 | |
3.Transforms的常用方法和运行实例
多看源代码,源代码中直接有示例,正确率杠杠的
简介
Transforms 是指对原始输入数据(如图像、文本、音频)或模型中间结果进行处理和修改的一系列操作。它们的主要目的是将原始数据转化为更适合模型训练、评估或推理的形式,或者是为了增强模型的性能和鲁棒性。
| Transform | 作用 |
|---|---|
transforms.ToTensor() |
将 PIL Image 或 ndarray 转换为 Tensor,且会将像素值从 [0, 255] 归一化到 [0.0, 1.0]。 |
transforms.Normalize(mean, std) |
对 Tensor 图像进行归一化(标准化):输出 = (输入 - mean) / std,通常用于模型训练时统一输入分布。 |
transforms.Resize(size) |
将输入图像缩放到指定的尺寸(保持纵横比或指定新尺寸)。 |
transforms.CenterCrop(size) |
从图像中心裁剪指定大小。 |
transforms.RandomCrop(size) |
随机裁剪图像,用于数据增强。 |
transforms.RandomHorizontalFlip(p=0.5) |
以概率 p 水平翻转图像,用于数据增强。 |
transforms.RandomVerticalFlip(p=0.5) |
以概率 p 垂直翻转图像。 |
transforms.RandomRotation(degrees) |
随机旋转图像一定角度范围,用于增加模型鲁棒性。 |
transforms.ColorJitter(brightness, contrast, saturation, hue) |
随机改变图像亮度、对比度、饱和度、色调,增强多样性。 |
transforms.Grayscale(num_output_channels=1) |
将图像转换为灰度图像。 |
transforms.RandomResizedCrop(size) |
随机裁剪图像并缩放为指定大小,常用于训练。 |
transforms.RandomAffine(degrees, translate, scale, shear) |
随机执行仿射变换(旋转、平移、缩放、剪切),提升泛化能力。 |
transforms.Lambda(func) |
应用自定义函数 func,用于特殊的自定义操作。 |
transforms.Compose([...]) |
将多个变换操作组合在一起,按顺序执行。 |
1 | |
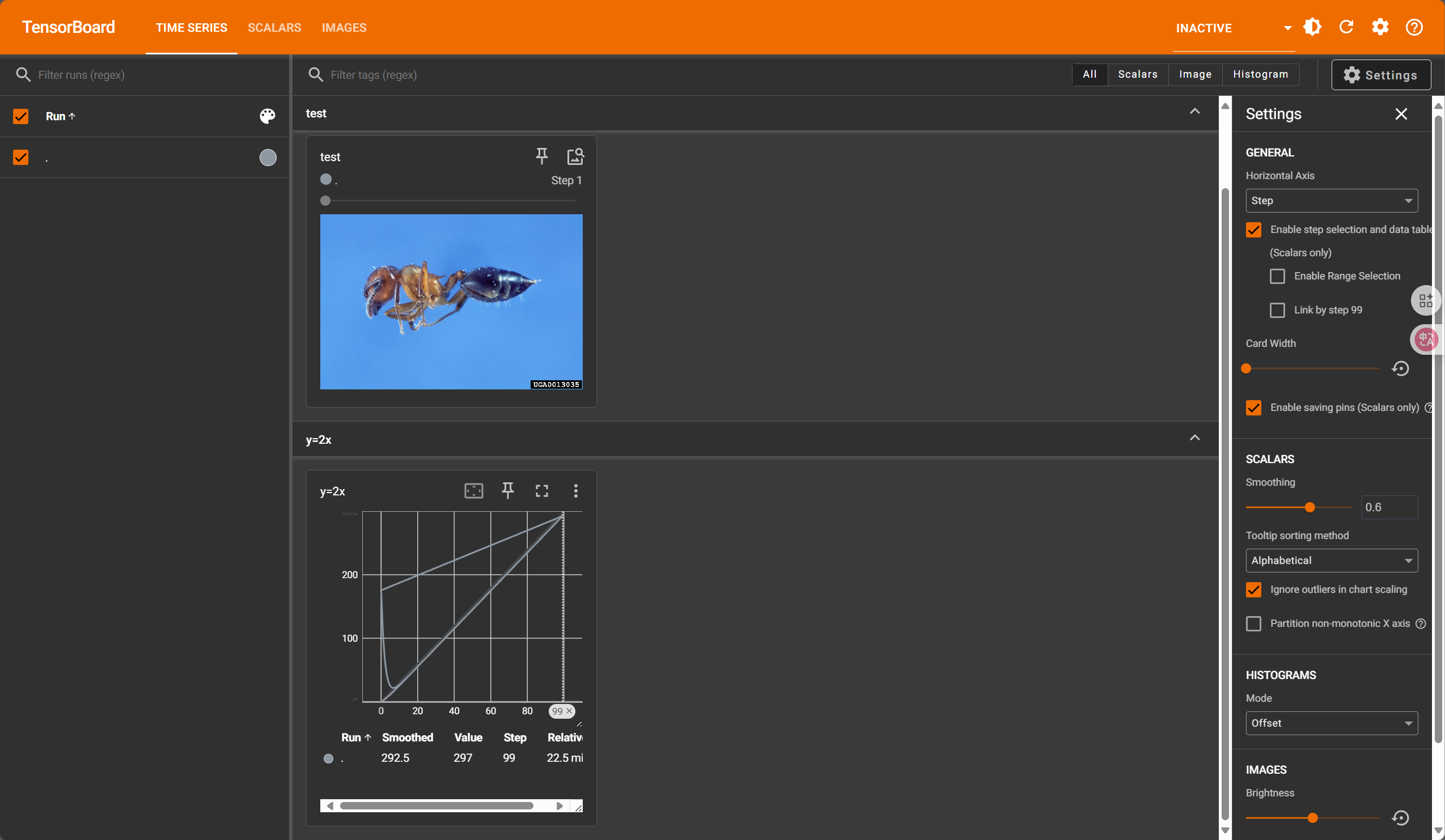
运行截图(tensorboard –logdir=logs):
4.torchvision中数据集的使用
:::info
如何下载/使用他人数据集
:::
1 | |
5.DataLoader的使用
1 | |
6.神经网络-nn.Module的使用

Moudle
- base classes for all neural network modules
- Moudles can also contain other Moudlers ,allowing them to be nested in a tree structure. You can assign the submodules as regular attributes
1 | |
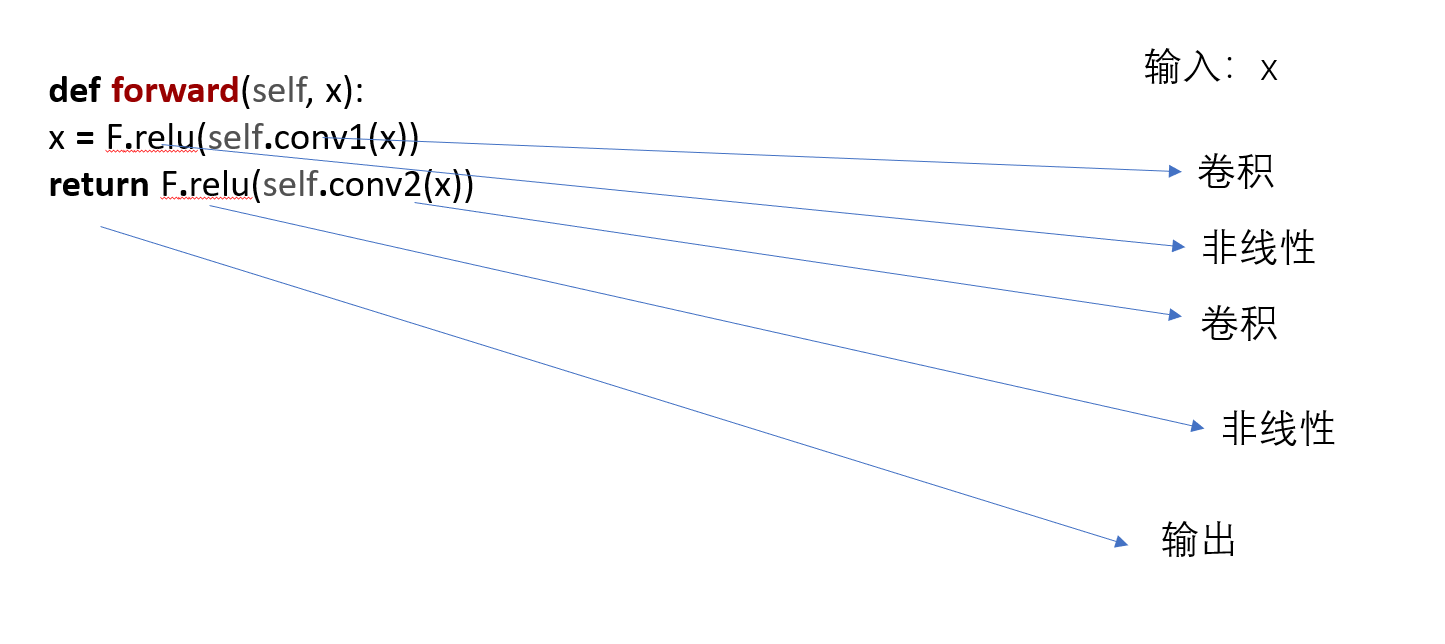
7.神经网络-卷积层
卷积
https://docs.pytorch.org/docs/stable/generated/torch.nn.Conv2d.html
1 | |
公式讲解
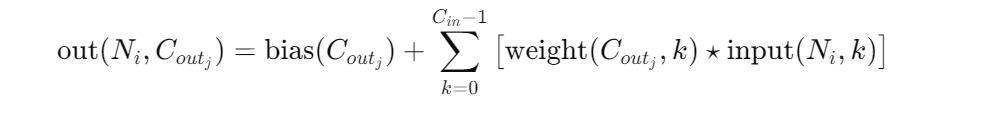

conv2d Parameters
- in_channels (int) – Number of channels in the input image
- out_channels (int) – Number of channels produced by the convolution
- kernel_size (int or tuple) – Size of the convolving kernel
- stride (int or tuple, optional) – Stride of the convolution. Default: 1
- padding (int,__ tuple or str, optional) – Padding added to all four sides of the input. Default: 0
- dilation (int or tuple, optional) – Spacing between kernel elements. Default: 1
- groups (int, optional) – Number of blocked connections from input channels to output channels. Default: 1
1 | |
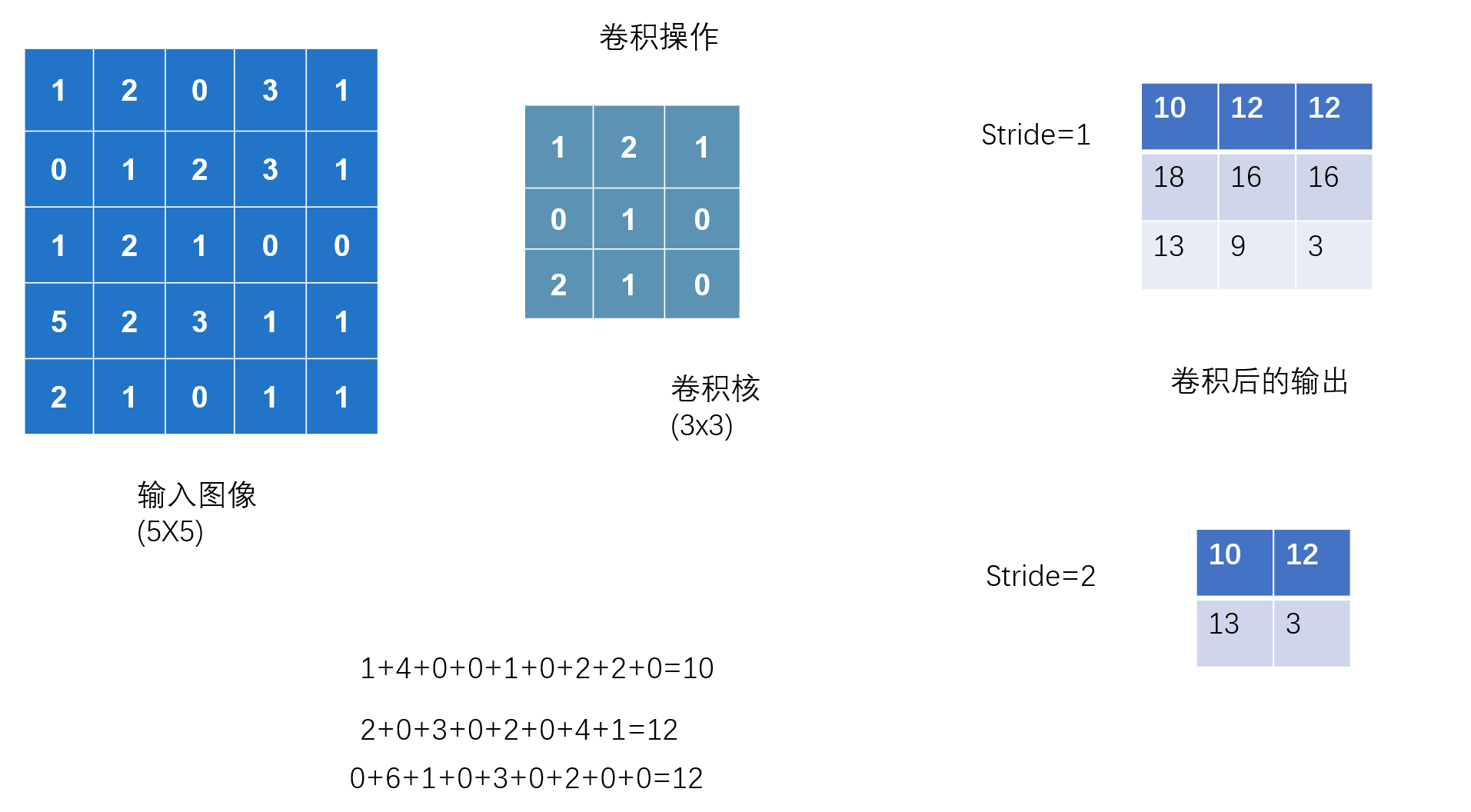
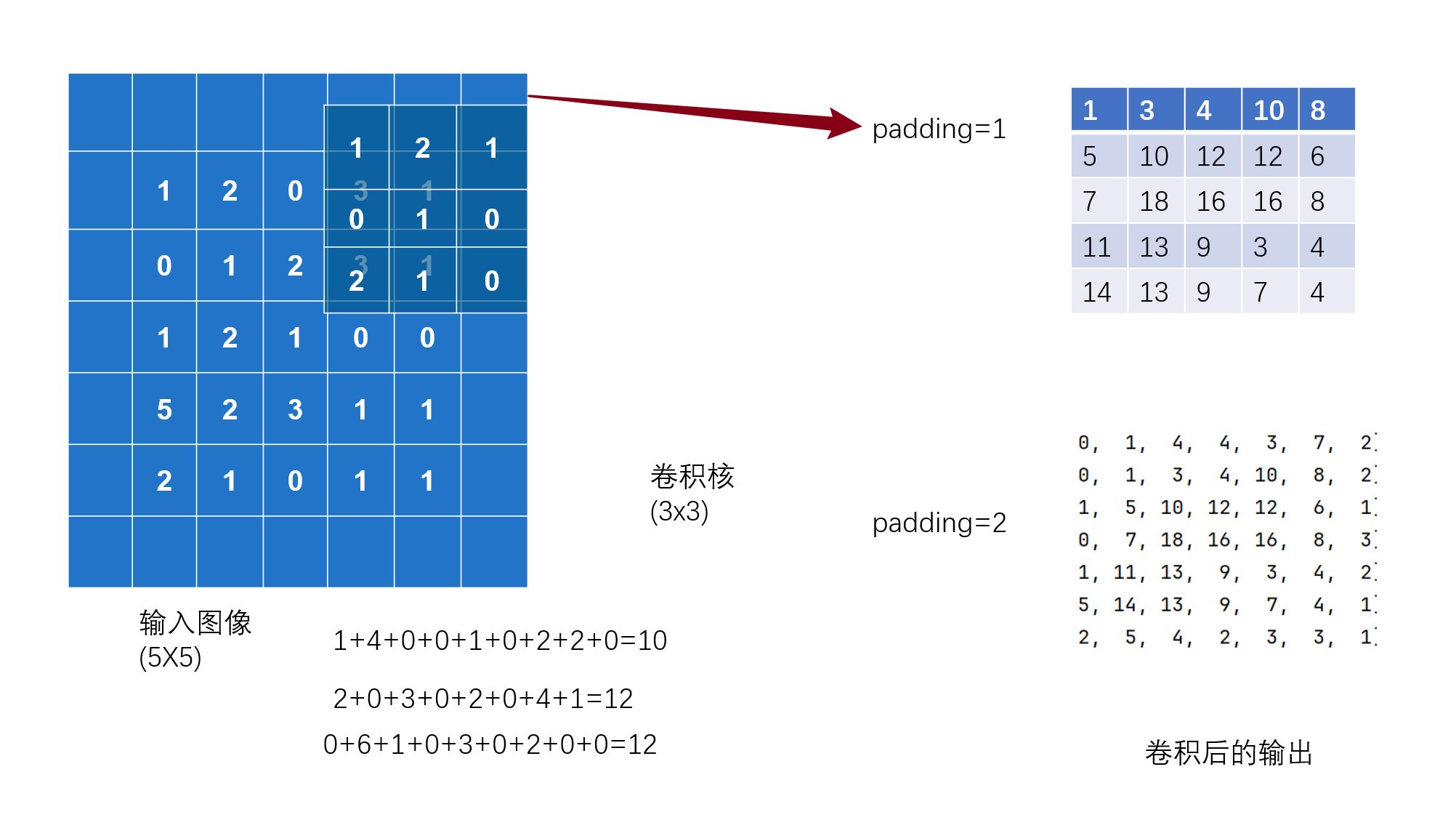
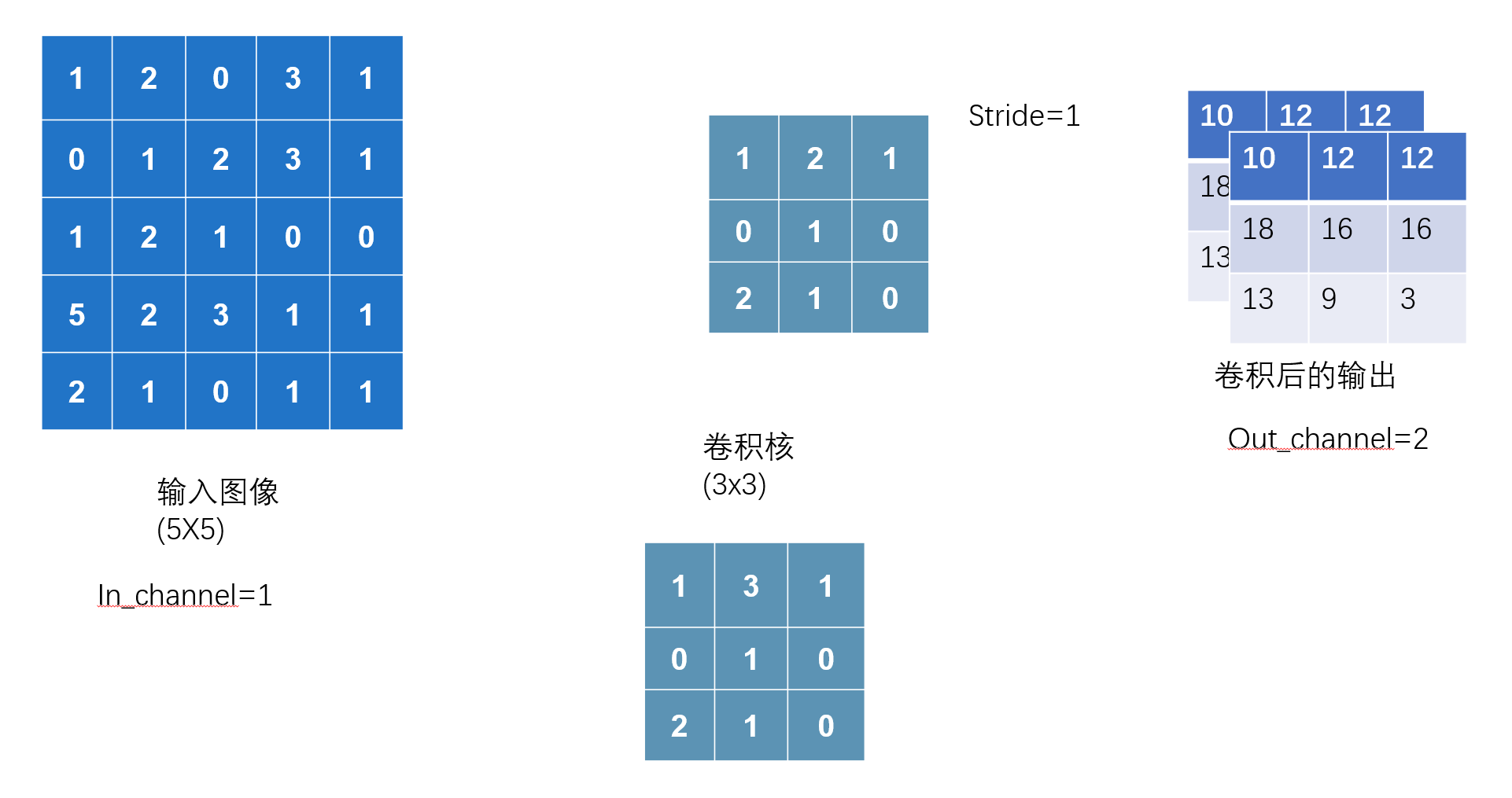
卷积层的使用
1 | |
8.神经网络-池化层
https://docs.pytorch.org/docs/stable/nn.html#pooling-layers
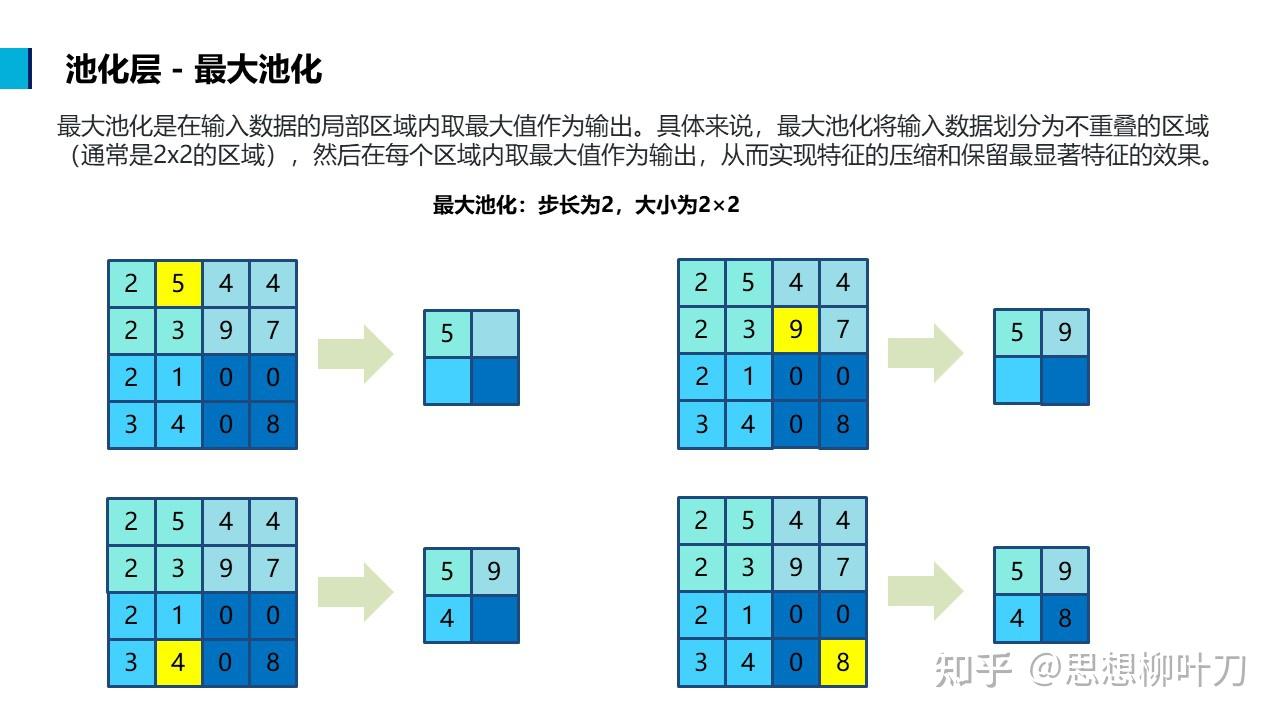
池化层(Pooling Layer)是深度学习神经网络中常用的一种层,用于减少特征图的空间尺寸,同时保留重要信息。池化层通常紧跟在卷积层之后,通过对特征图进行下采样来减少参数数量,降低计算复杂度,并且有助于防止过拟合。
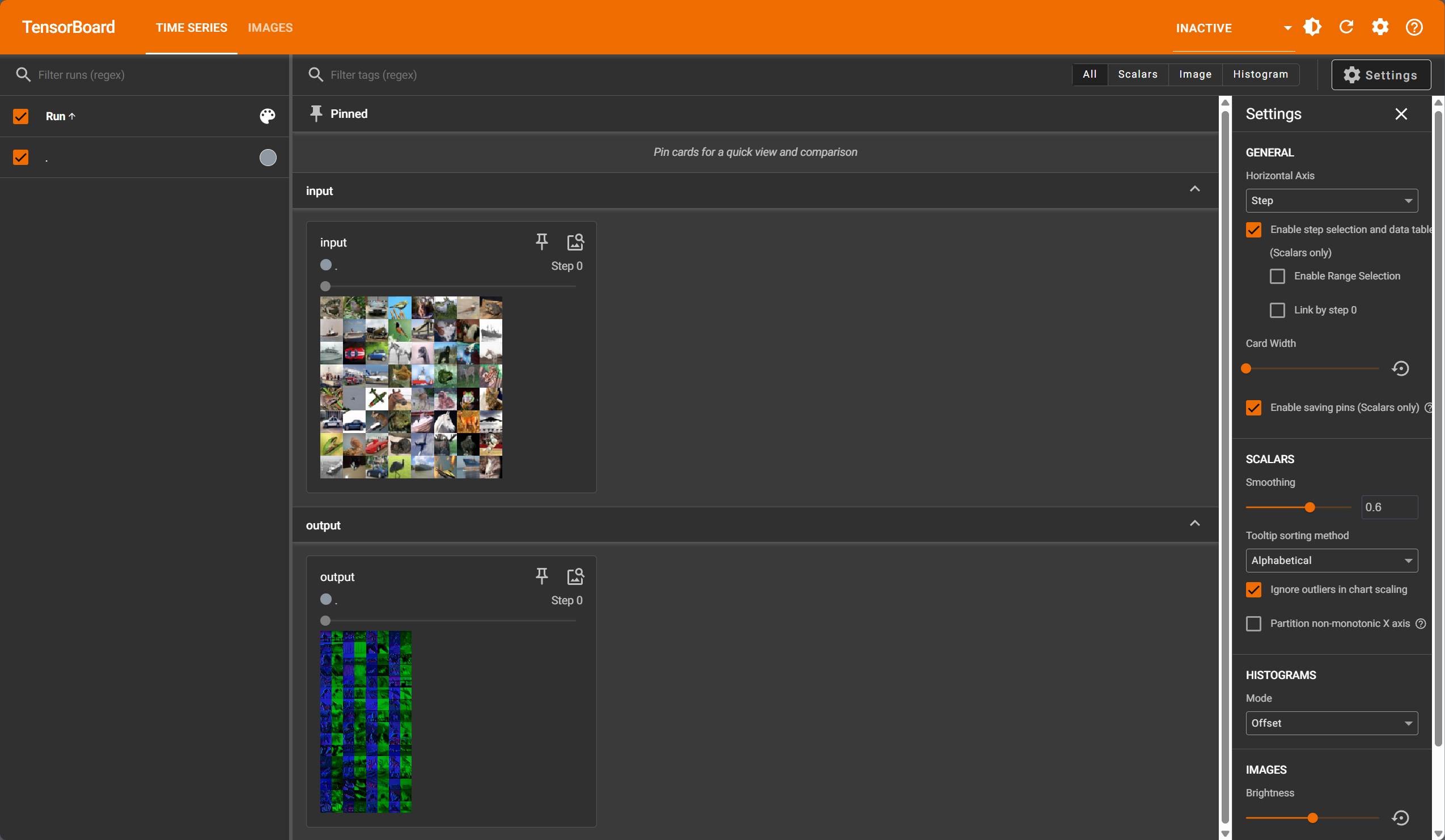
最大池化选取池化窗口中的最大值作为输出,平均池化计算池化窗口中的平均值作为输出。
最大池化
优点包括:
- 特征不变性:最大池化能够保留局部区域内最显著的特征,使得模型对目标的位置变化具有一定的不变性。
- 降维:通过取每个区域内的最大值,可以减少数据的空间尺寸,降低模型的复杂度,加快计算速度。
- 减少过拟合:最大池化可以减少模型的参数数量,有助于减少过拟合的风险。
1 | |
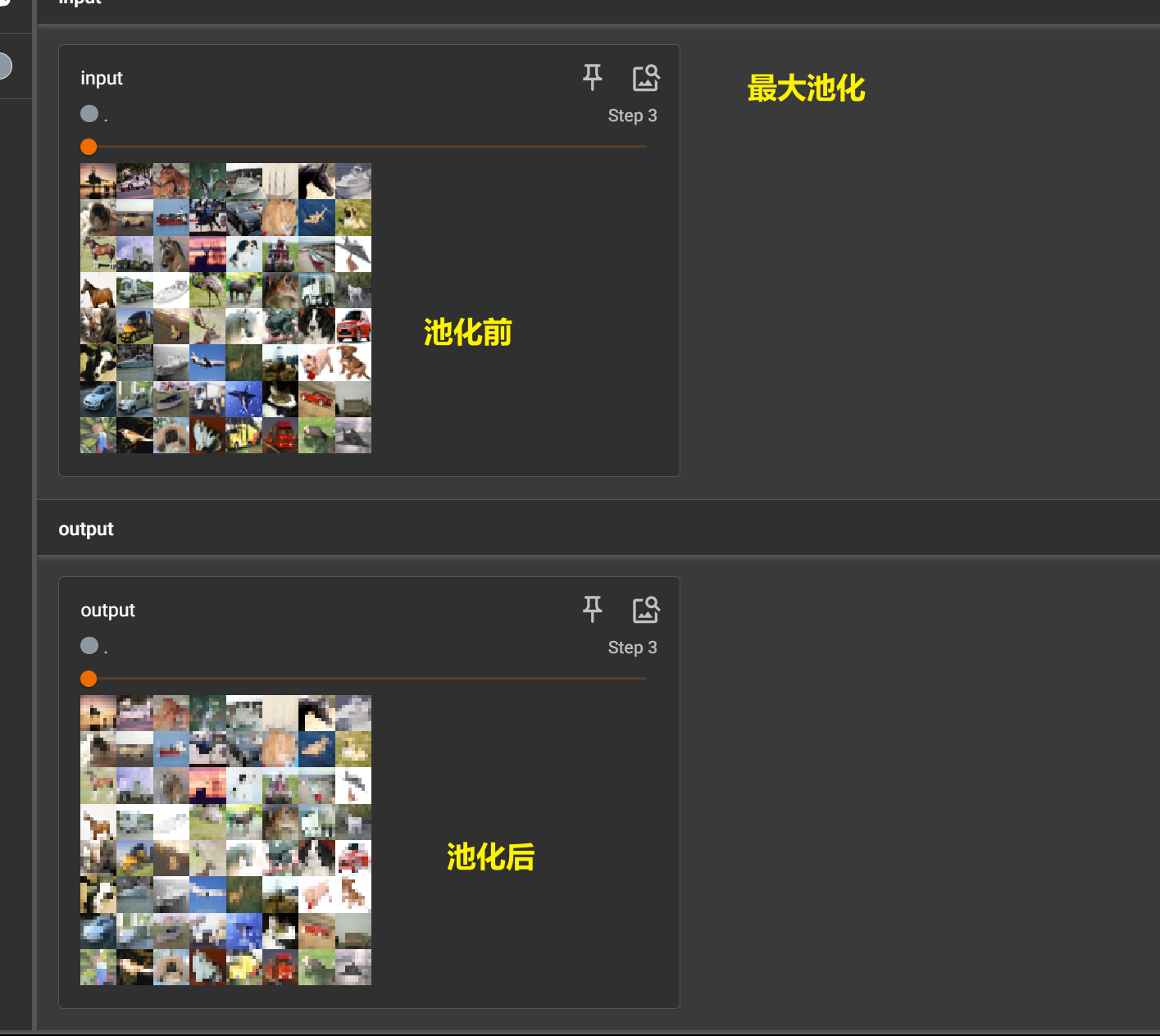
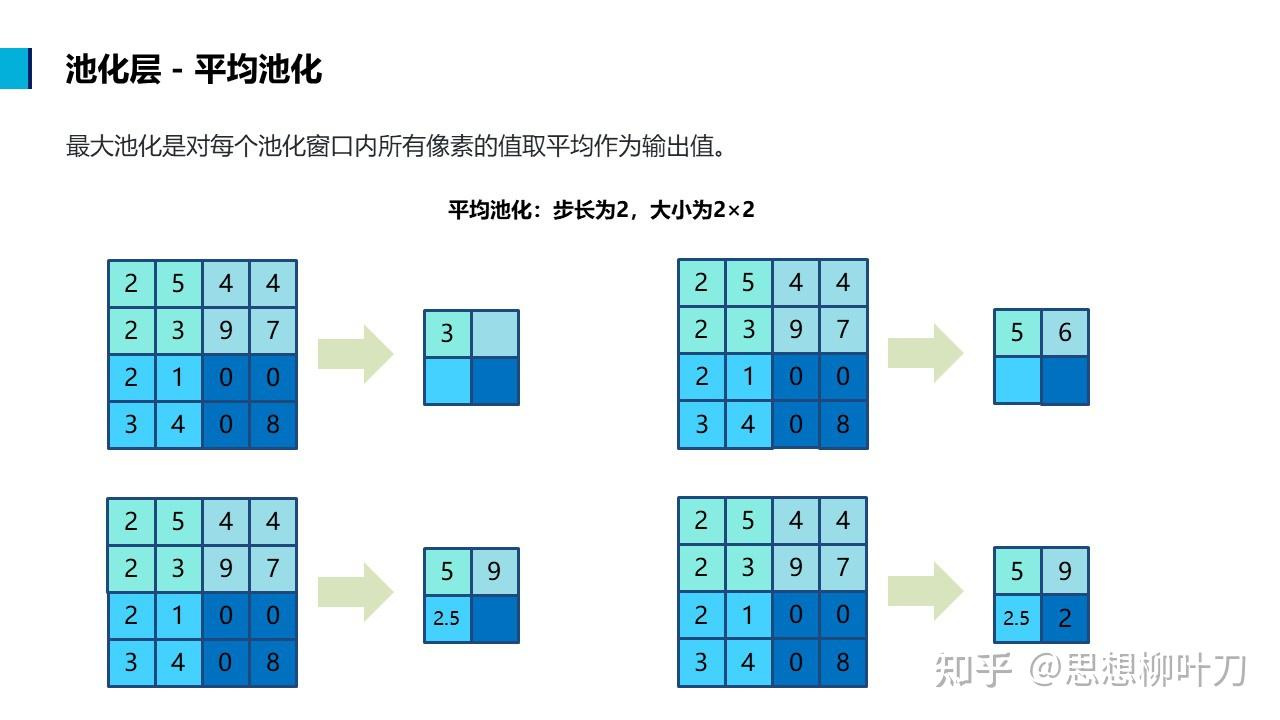
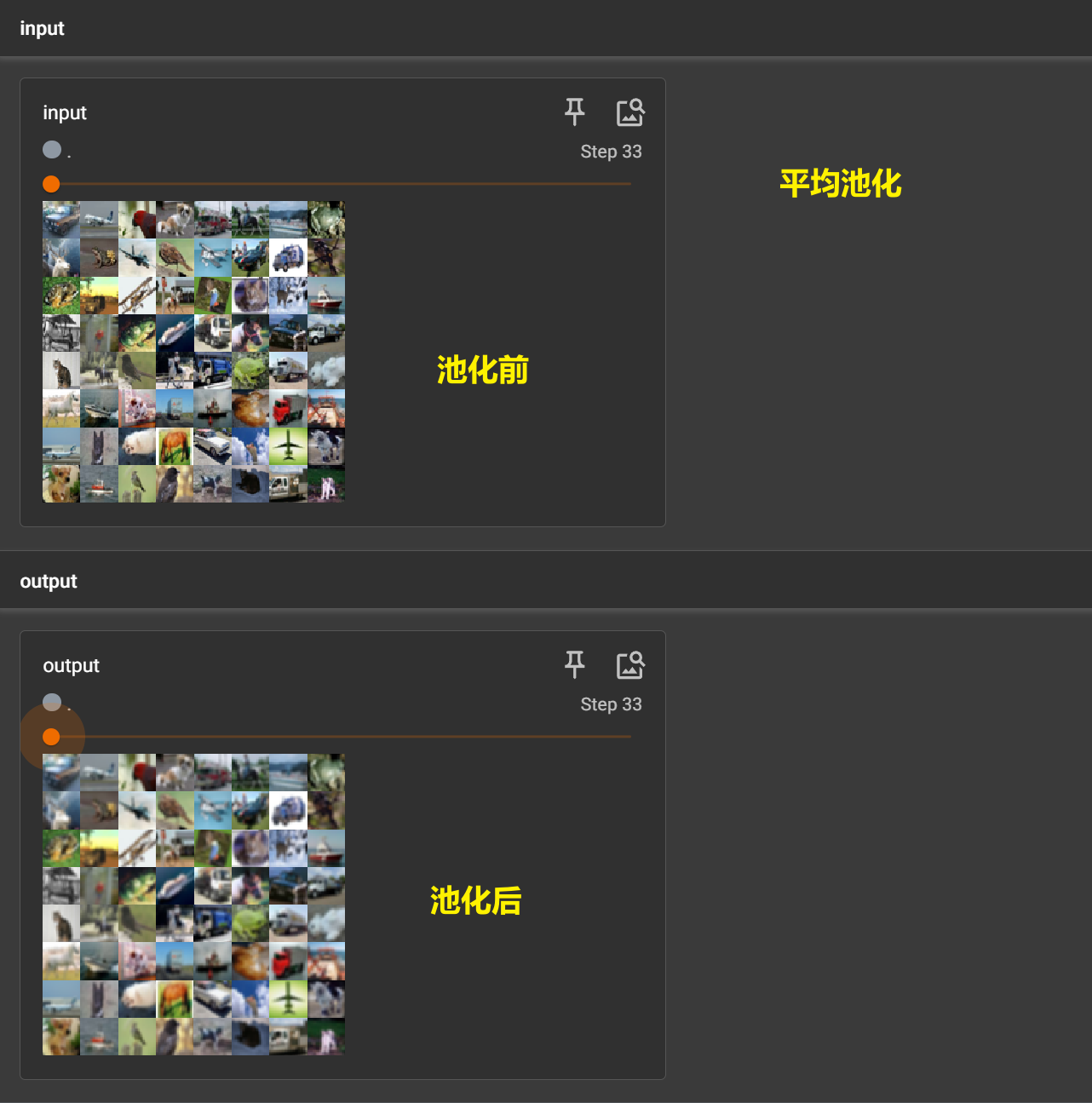
平均池化
在平均池化中,对于每个池化窗口(通常是一个矩形区域),将窗口内所有像素的值取平均作为输出值。这个过程可以看作是对特征图进行降采样,减少特征图的尺寸,同时保留主要特征。平均池化的主要优点是能够保留更多的信息,相比于最大池化(Max Pooling),平均池化更加平滑,有助于保留更多细节信息。
1 | |
9.神经网络-非线性激活
- 提升模型的泛化能力
- 所有的
激活函数本质都是一种非线性变换。 - 非线性变换是深度学习“能学到复杂东西”的根本原因
1 | |
10.神经网络-线性层及其他层

正则化层(Normalization Layers)
https://docs.pytorch.org/docs/stable/nn.html#normalization-layers
1 | |
11.神经网络-Sequential小实战
CIFAR 10 model
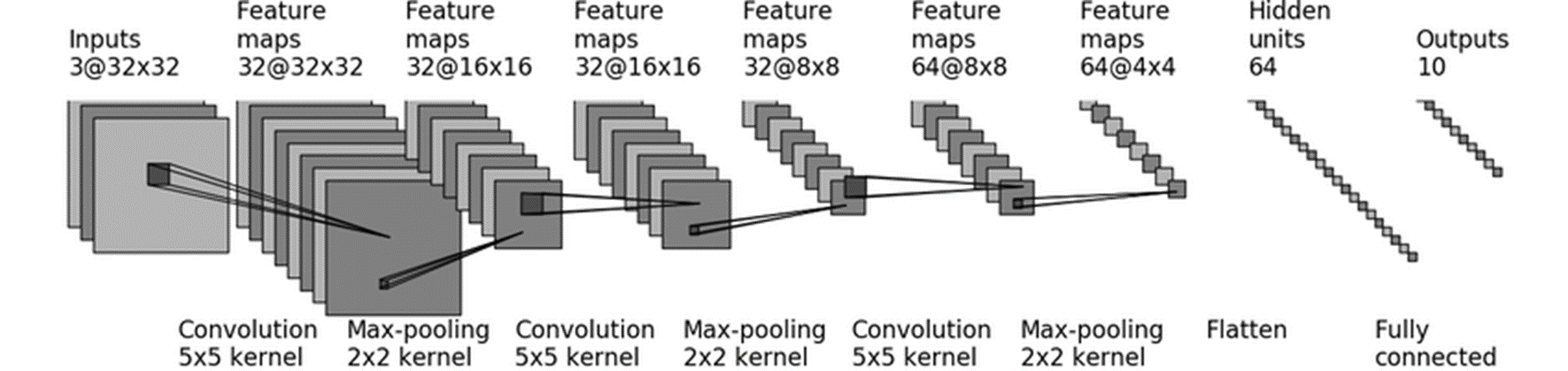

代码
1 | |
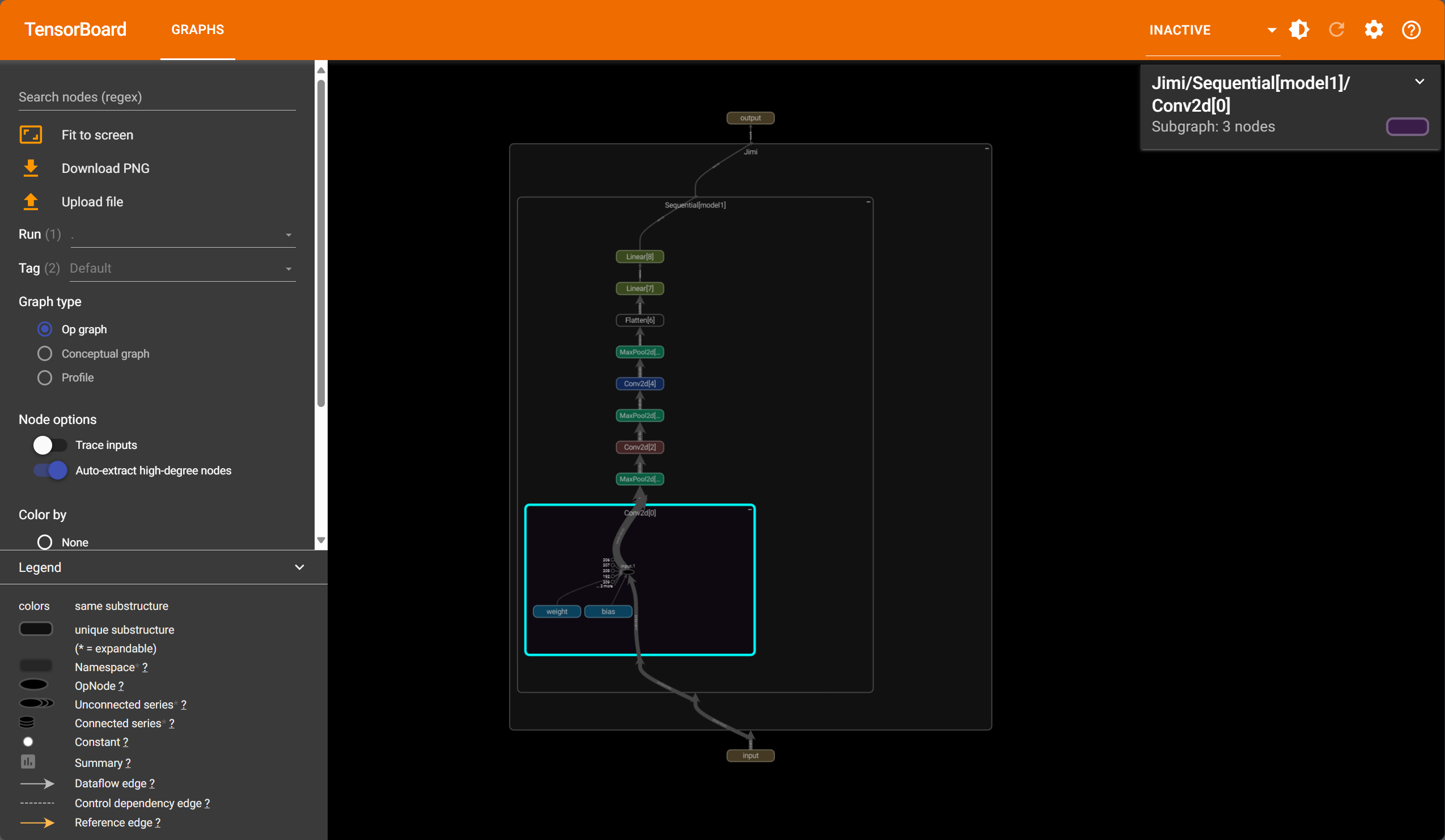
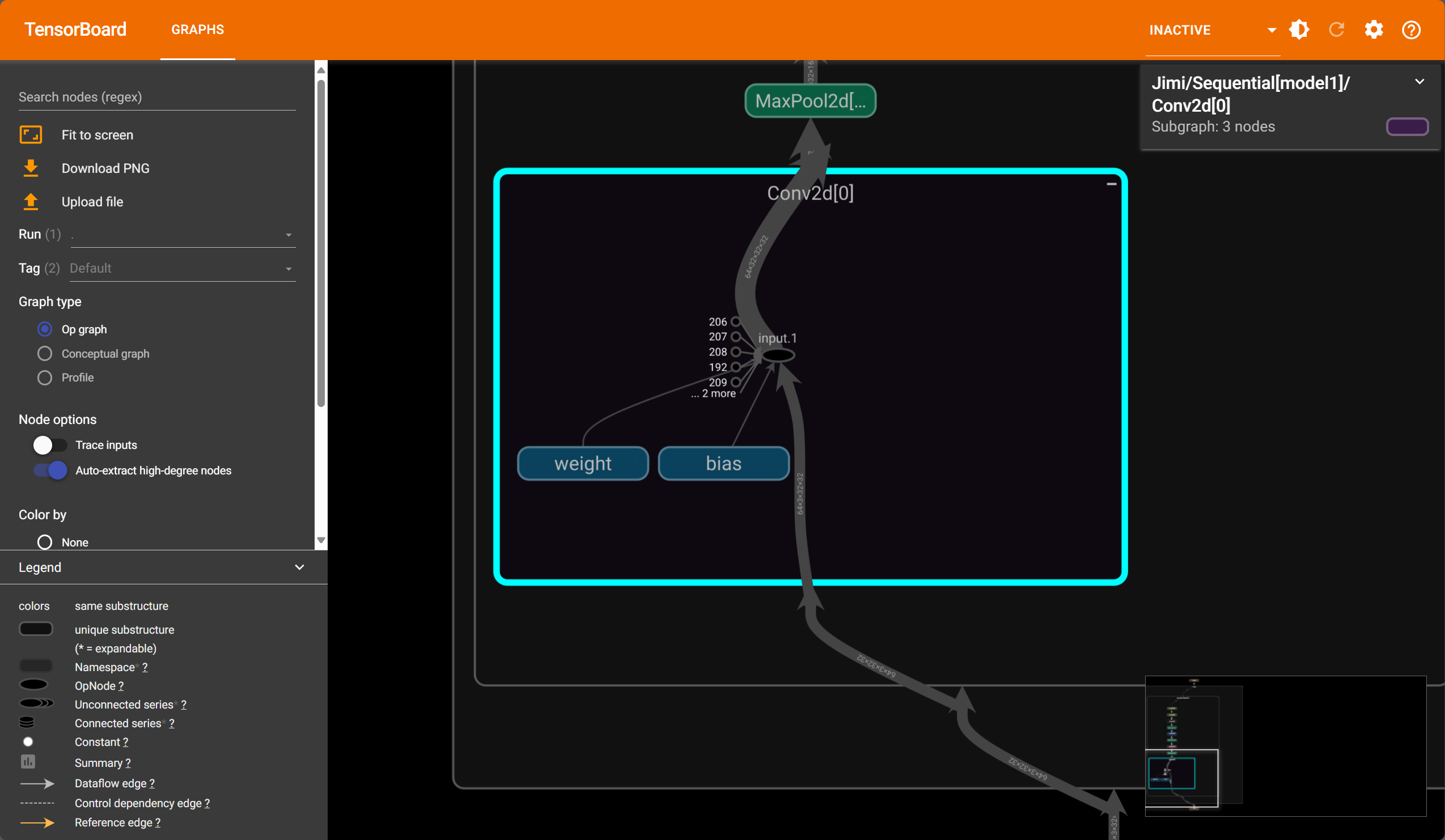
12.神经网络-损失函数与反向传播
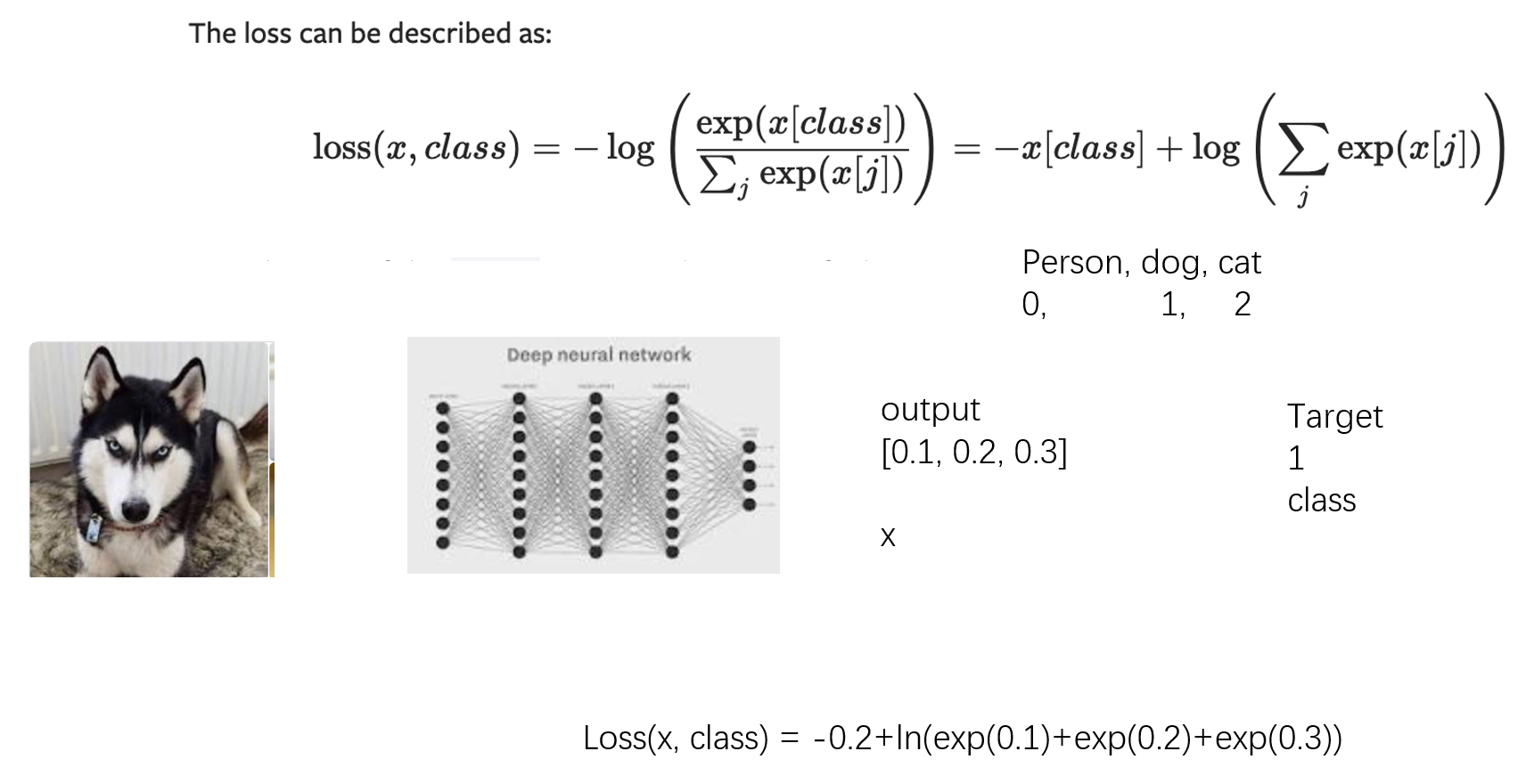
损失函数
损失函数是用来衡量模型预测结果与真实结果之间差距的函数。它给出一个标量值,表示模型当前的预测有多差,损失值越小,模型预测越准确。
在训练过程中,我们的目标就是最小化损失函数,通过不断调整模型参数,使模型预测结果越来越接近真实标签。
反向传播是用于计算损失函数对神经网络中每个参数的梯度的算法。
1 | |
1 | |
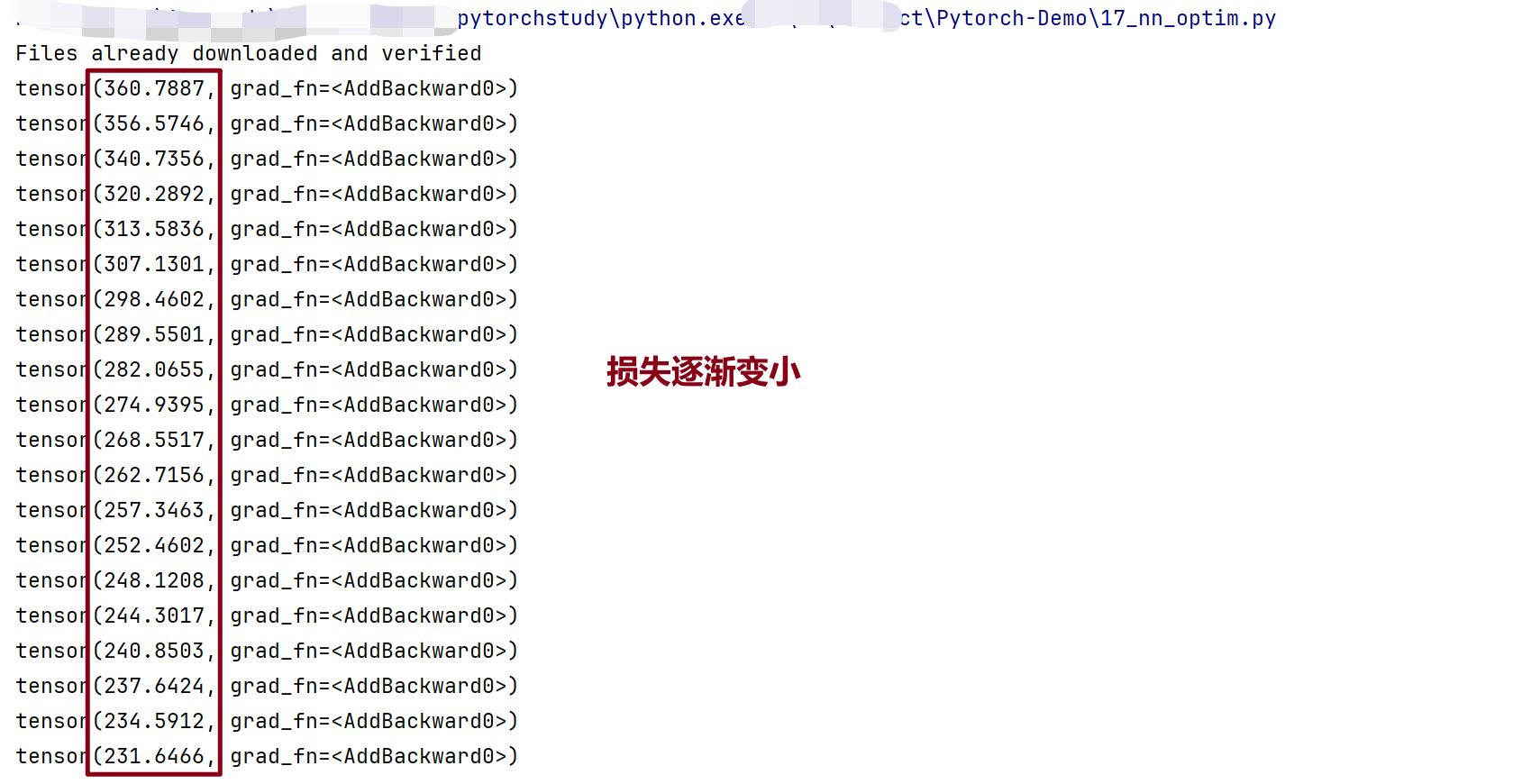
13.神经网络-优化器(训练)
https://docs.pytorch.org/docs/stable/optim.html

1 | |
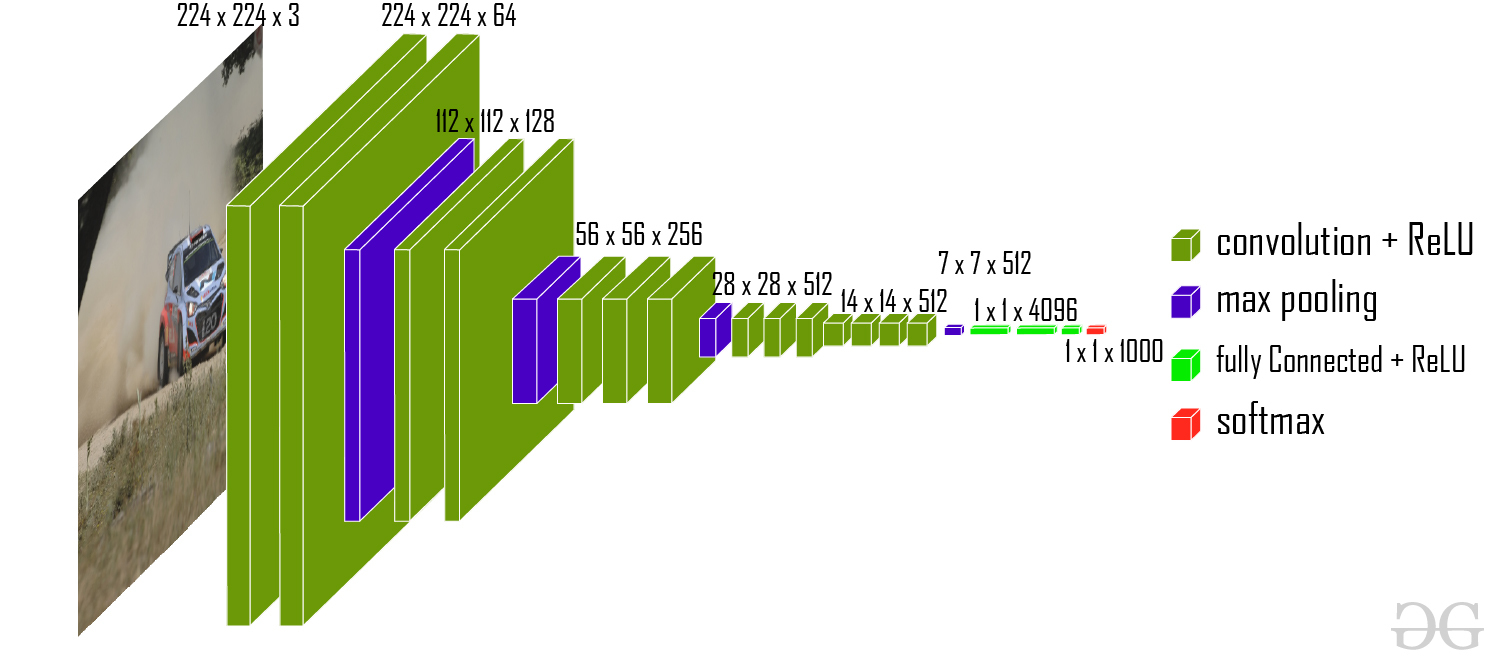
14.现有模型的使用和修改
模型:VGG-16
1 | |
15.模型的保存与读取
方法一:
模型的保存:
不安全
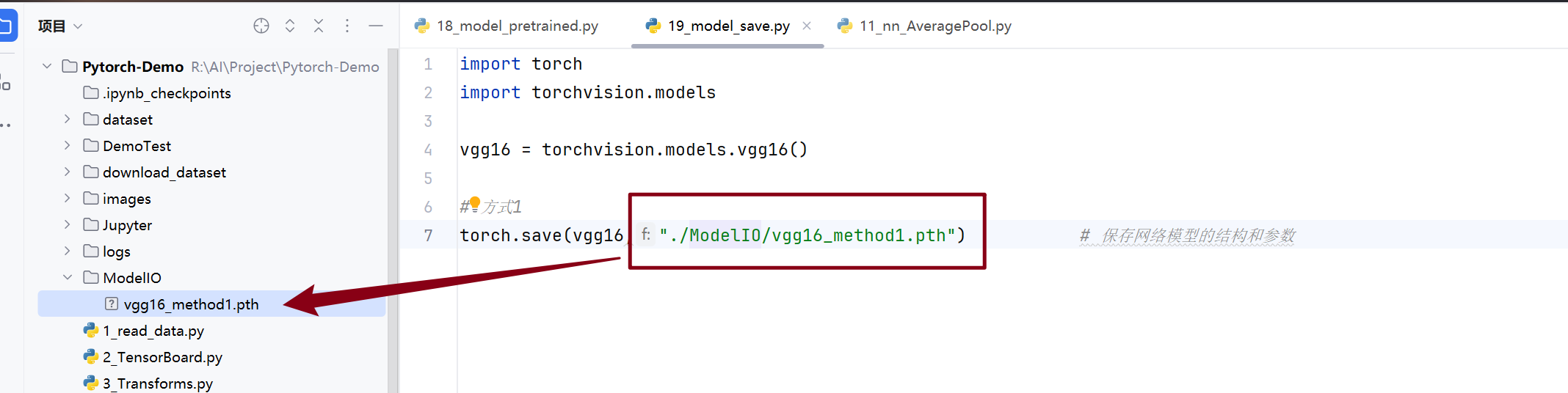
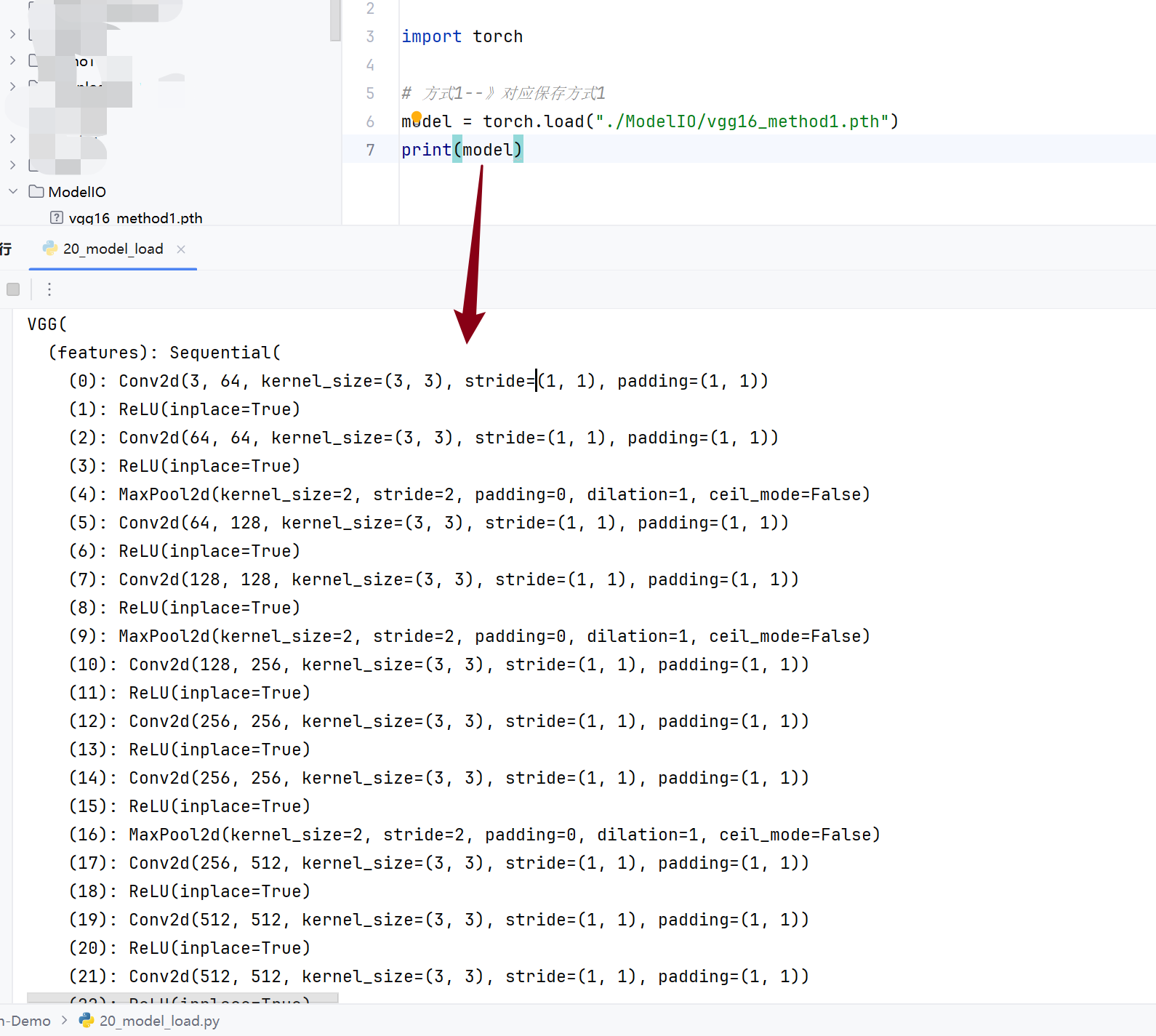
模型的读取:
方法二:
保存:
官方推荐:状态 _ 字典
保存成字典形式,占用空间小

读取:
直接读取的话是字典形式
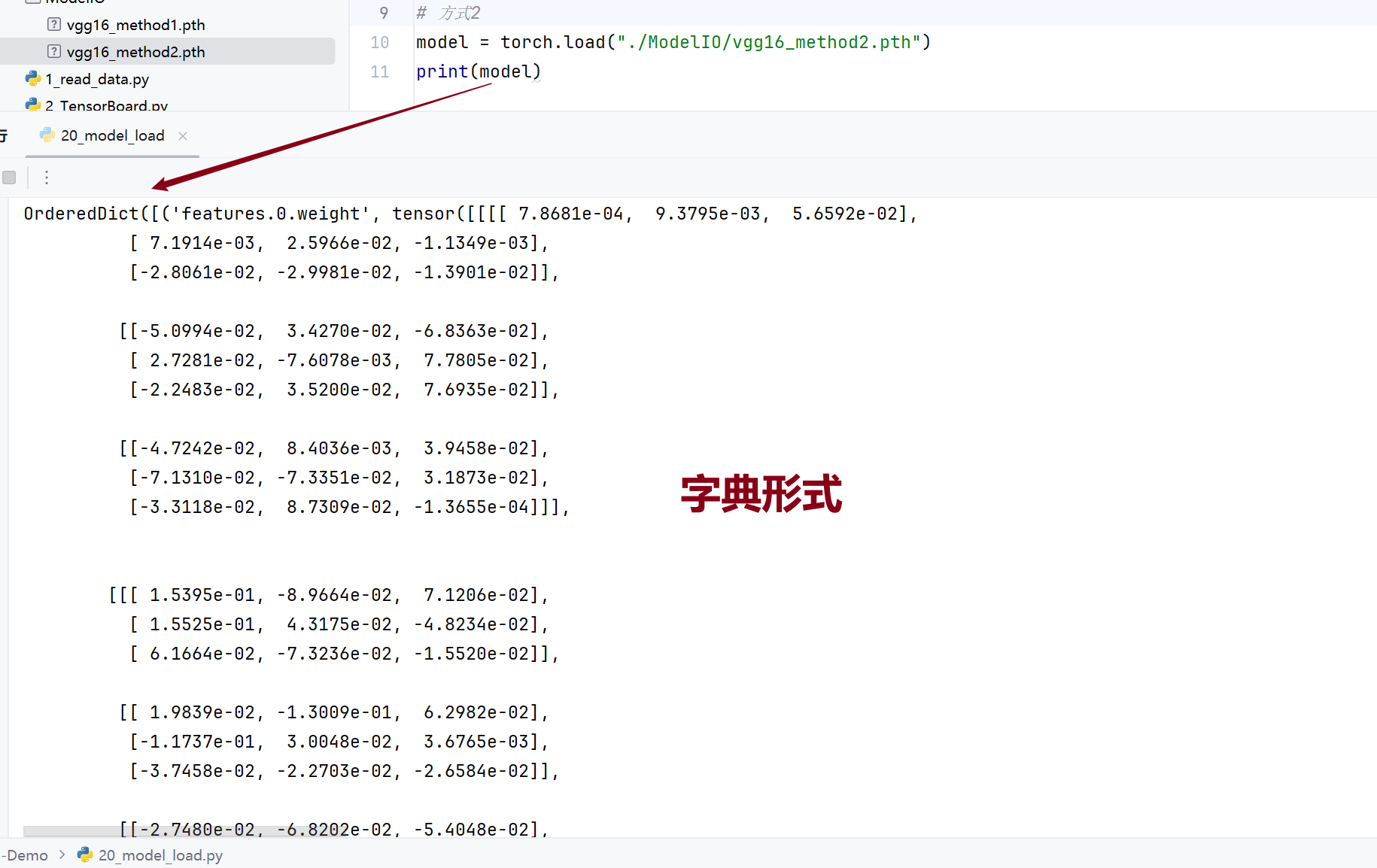
需要转换一下
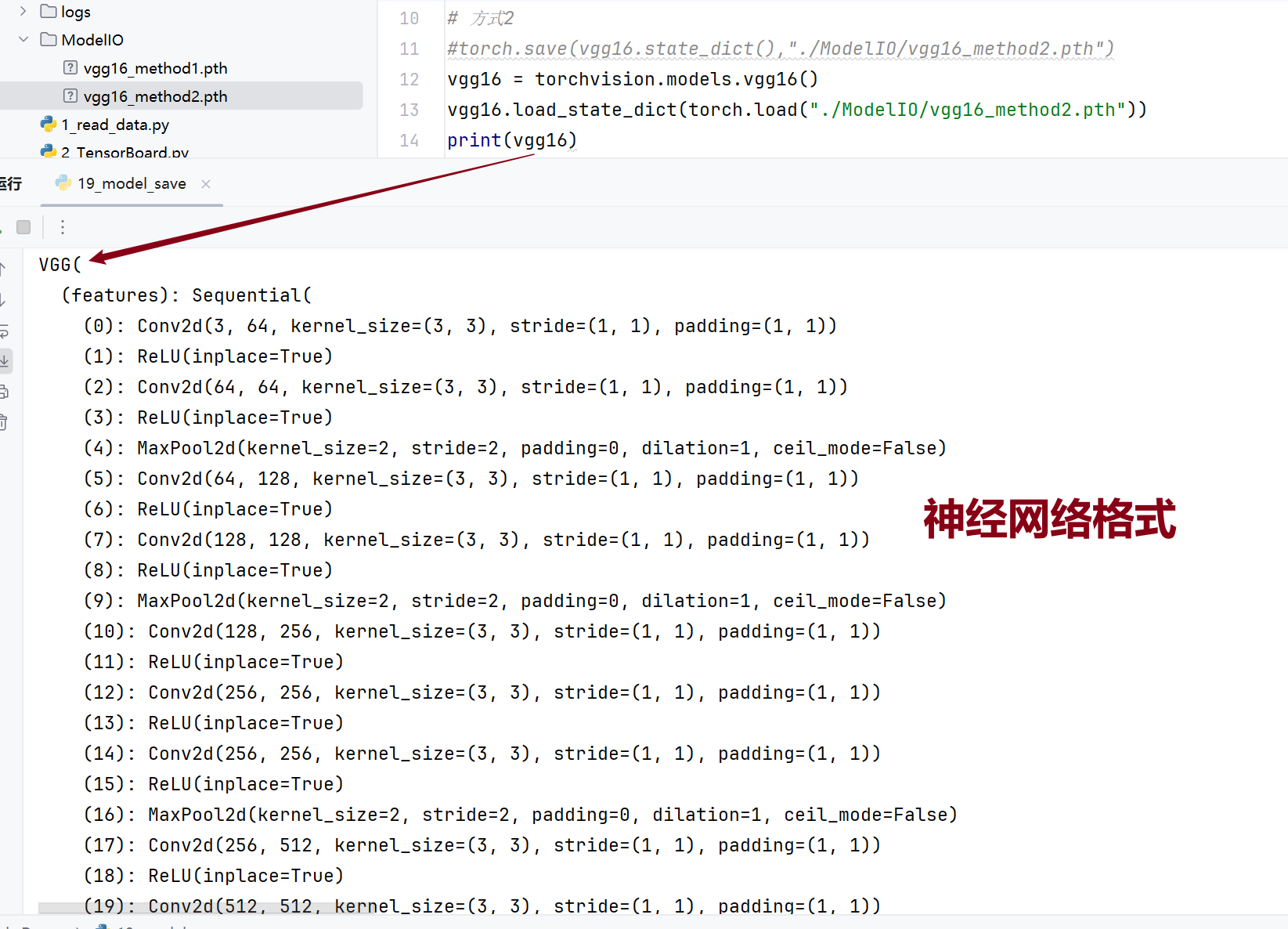
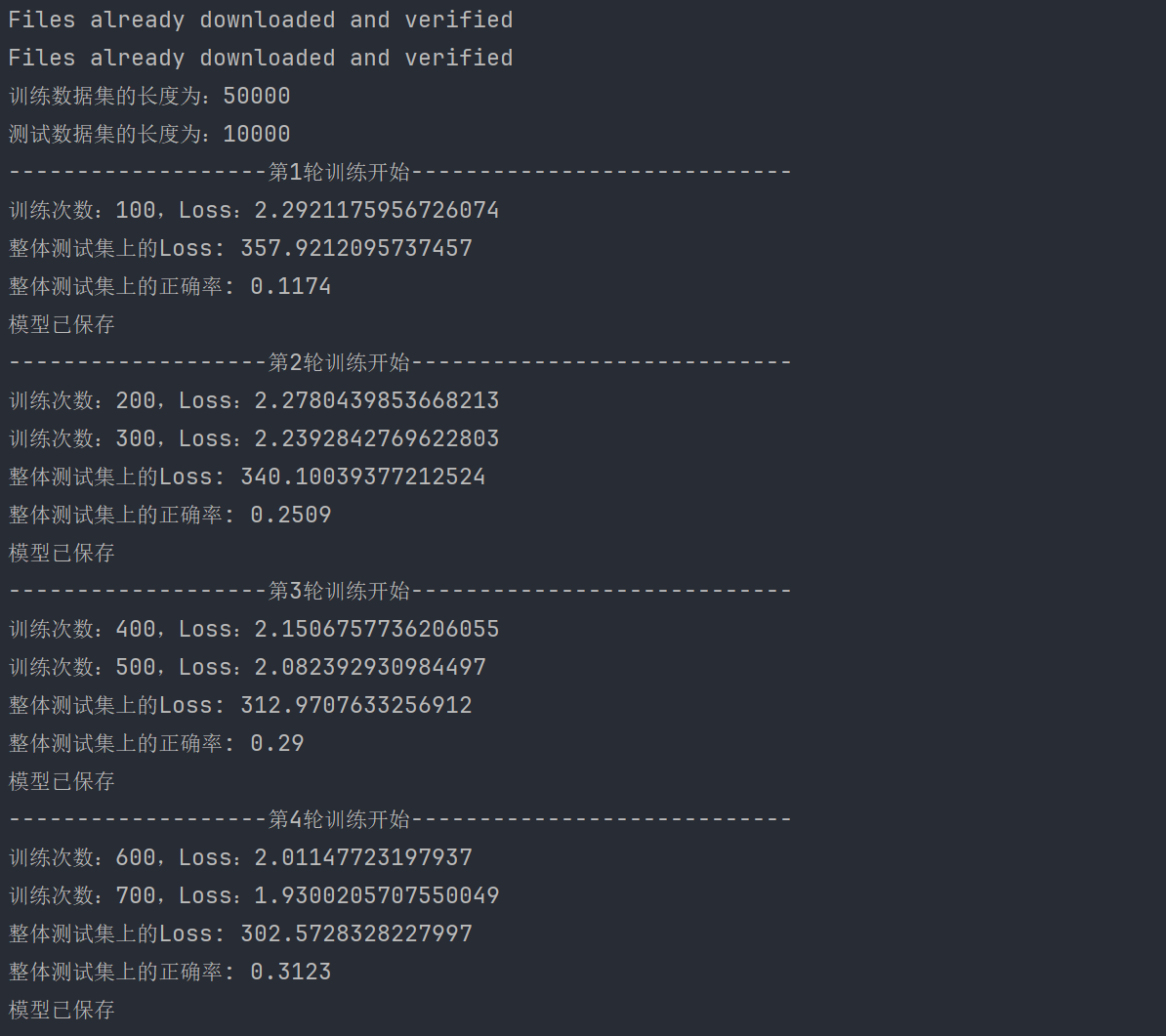
16.完整的模型训练流程
数据集:CLFAR10
1 | |
1 | |